




Definition:
In Natural language processing, Named Entity Recognition (NER) is a process where a sentence or a chunk of text is parsed through to find entities that can be put under categories like names, organizations, locations, quantities, monetary values, percentages, etc. With named entity recognition, you can extract key information to understand what a text is about, or merely use it to collect important information to store in a database.

History:
The term “Named Entity (NE)” was born in the Message Understanding Conferences
(MUC) which influenced IE research in the U.S. in the 1990’s. At that time, MUC focused on Information Extraction tasks where structured information of company activities and defense related activities is extracted from unstructured text, such as newspaper articles. Outside the U.S., there have been several evaluation-based projects for NE. Around this time, the number of categories is limited to 7 to 10, and the NE taggers, automatic annotation systems for NE entities in unstructured text, are based on dictionaries and rules which were made by hand or some supervised learning technique. More recent and currently dominating technology is the supervised learning techniques like Decision Tree, Support Vector Machine, etc.
How to choose between open source and cloud engines ?
When you are looking for a NER engine, the first question you need to ask you is: which kind of engine am I going to choose?
Of course, the main advantage of open source NER engines is that they are open source. It means that this is free to use and you can use the code in the way you want. It allows you to potentially modify the source code, hyperparameterize the model. Moreover, you will have no trouble with data privacy because you will have to host the engine with your own server, which also means that you will need to set up this server, maintain it and insure you that you will have enough computing power to handle all the requests.
On the other hand, cloud NER engines are paying but the AI provider will handle the server for you, maintain and improve the model. In this case, you have to accept that your data will transit to the provider cloud. In exchange, the provider is processing millions of data to provide a very performant engine. The NER provider also has servers that can support millions of requests per second without losing performance or rapidity.
Now that you know the pros and cons of open source and cloud engines, please consider that there is a third option: build your own NER engine. With this option, you can build the engine based on your own data which guarantees you good performance. You will also be able to keep your data safe and private. However, you will have the same constraint of hosting your engine. Of course, this option can be considered only if you have data science abilities in your company. Here is a summary of when to choose between using existing engines (cloud or open source) and build your own one:
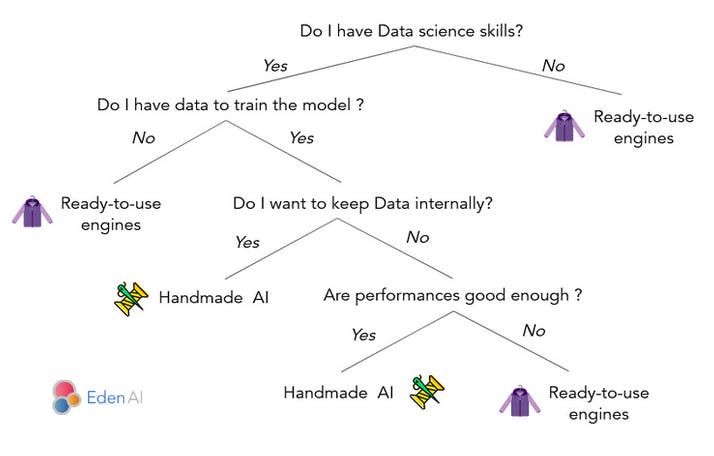
Open Source NER engines:
There are multiple open source NER engines available, you can find the majority on github. Here are the most famous ones:
spaCy:
spaCy is a library for advanced Natural Language Processing in Python and Cython. It's built on the very latest research, and was designed from day one to be used in real products.
spaCy comes with pretrained pipelines and currently supports tokenization and training for 60+ languages. It features state-of-the-art speed and neural network models for tagging, parsing, named entity recognition, text classification and more, multi-task learning with pre trained transformers like BERT, as well as a production-ready training system and easy model packaging, deployment and workflow management. spaCy is commercial open-source software, released under the MIT license.
NLTK:
NLTK -- the Natural Language Toolkit -- is a suite of open source Python modules, data sets, and tutorials supporting research and development in Natural Language Processing. NLTK requires Python version 3.7, 3.8, 3.9 or 3.10. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries. You can access to NLTK documentation here.
StanfordNLP:
StanfordNLP is a Python natural language analysis package. It contains tools, which can be used in a pipeline, to convert a string containing human language text into lists of sentences and words, to generate base forms of those words, their parts of speech and morphological features, and to give a syntactic structure dependency parse, which is designed to be parallel among more than 70 languages, using the Universal Dependencies formalism.
You can also check other Python open source libraries for NER such as BERT which is provided by Google Research.
Cloud NER engines:
There are many cloud NER engines on the market and you will have issues choosing the right one. Here are some of the best providers of the market:
- Lettria
- Paralleldots
- MonkeyLearn
- Google Cloud Natural Language
- Amazon Comprehend
- Microsoft Azure Text Analytics
- IBM Watson
All those NER providers can provide you good performance for your project. Depending on the language, the quality, the format, the size of your documents, the best engine can vary between all these providers. The only way to know which provider to choose is to compare the performance with your own data.
Eden AI NER API:
This is where Eden AI enters in your process. Eden AI NER API allows you to use engines from all these providers with a unique API, a unique token and a simple Python documentation.
By using Eden AI, you will be able to compare all the providers with your data, change the provider whenever you want and call multiple providers at the same time. You will pay the same price per request as if you had subscribed directly to the providers APIs and you will not lose latency performance.
Here is how to use NER engines in Python with Eden AI SDK:
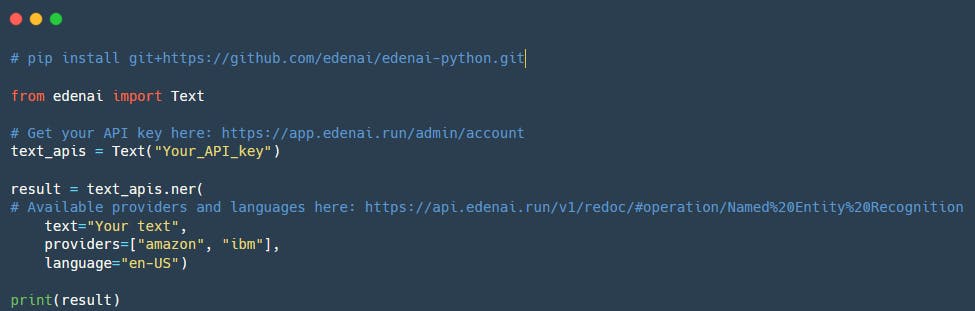
If you want to call another provider, you just need to change the value of the parameter “providers”. You can see all providers available in Eden AI documentation. Of course, you can call multiple providers in the same request in order to compare or combine them.
Conclusion
As you could see in this article, there are many options to use NER with Python. For developers who do not have data science skills or who want to quickly and simply use NER engines, there are many open source and cloud engines available. Each option presents pros and cons, you know have the clues to choose the best option for you.
If you choose a cloud NER engine, you will need some help to find the best one according to your data. Moreover, NER providers often update and train their models. It means that you may have to change your provider’s choice in the future to keep having the best performance for your project. With Eden AI, all this work is simplified and you can set up an NER engine in Python in less than 5 minutes, and switch to the best provider at any moment.
You can create your Eden AI account here and get your API token to start implementing an NER engine in Python!