



In today’s fast-paced digital world, the ability to extract and analyze information from documents efficiently is paramount. Whether you’re dealing with invoices, receipts, contracts, or any other type of document, Optical Character Recognition (OCR) technology plays a pivotal role in automating data extraction. One of the emerging players in the OCR landscape is Eden AI, which offers a suite of powerful OCR tools to streamline document parsing.
In this article, we will show you how to use OCR to draw bounding boxes on .pdf files.
What is Optical Character Recognition (OCR)?
OCR is a technology that converts different types of documents, such as scanned paper documents, PDF files, or images, into editable and searchable data. It accomplishes this by recognizing text characters within these documents (such as invoice OCR, resume OCR, bank check OCR, ID card OCR, etc) and then transforming them into machine-readable text.

OCR technology is not only used for data extraction but also for making scanned documents more accessible, such as converting printed books into digital formats or enabling text-to-speech for visually impaired individuals.
How does OCR work?
OCR technology follows a systematic process to convert images and scanned documents into text:
1. Image Preprocessing: The OCR software first analyzes and preprocesses the input image to enhance the quality of the text extraction. This may involve tasks like image de-skewing, noise reduction, and contrast adjustment.
2. Text Detection: OCR algorithms identify areas of the image that contain text, often referred to as bounding boxes, to focus on extracting text content from these regions.
3. Character Recognition: The system recognizes individual characters within the bounding boxes and maps them to their corresponding textual representations. By utilizing the Eden AI platform, it is also possible to draw bounding boxes on a processed PDF file to highlight specific words within the document.
4. Post-processing: To improve accuracy and readability, OCR tools often employ post-processing techniques like spell-checking and text formatting.
OCR Optical Character Recognition

OCR with Eden AI
Eden AI simplifies the use and integration of AI technologies by providing a unique API that gives access to the best AI APIs and a powerful management platform. Eden AI covers a wide range of AI technologies: Image, Text & NLP, Speech & Audio, OCR & Document Parsing, Machine Translation, Video.

When you make a call to parse a document using the Eden AI OCR API, the API returns a standardized response that includes the extracted text from each row in the file, as well as the bounding boxes for each word.
Apart from obtaining the bounding boxes, you may also draw them on the processed PDF file, in order to highlight specific words within the document. To illustrate this process, we will be implementing it using the Python programming language.
Step 1. Extract the bounding boxes
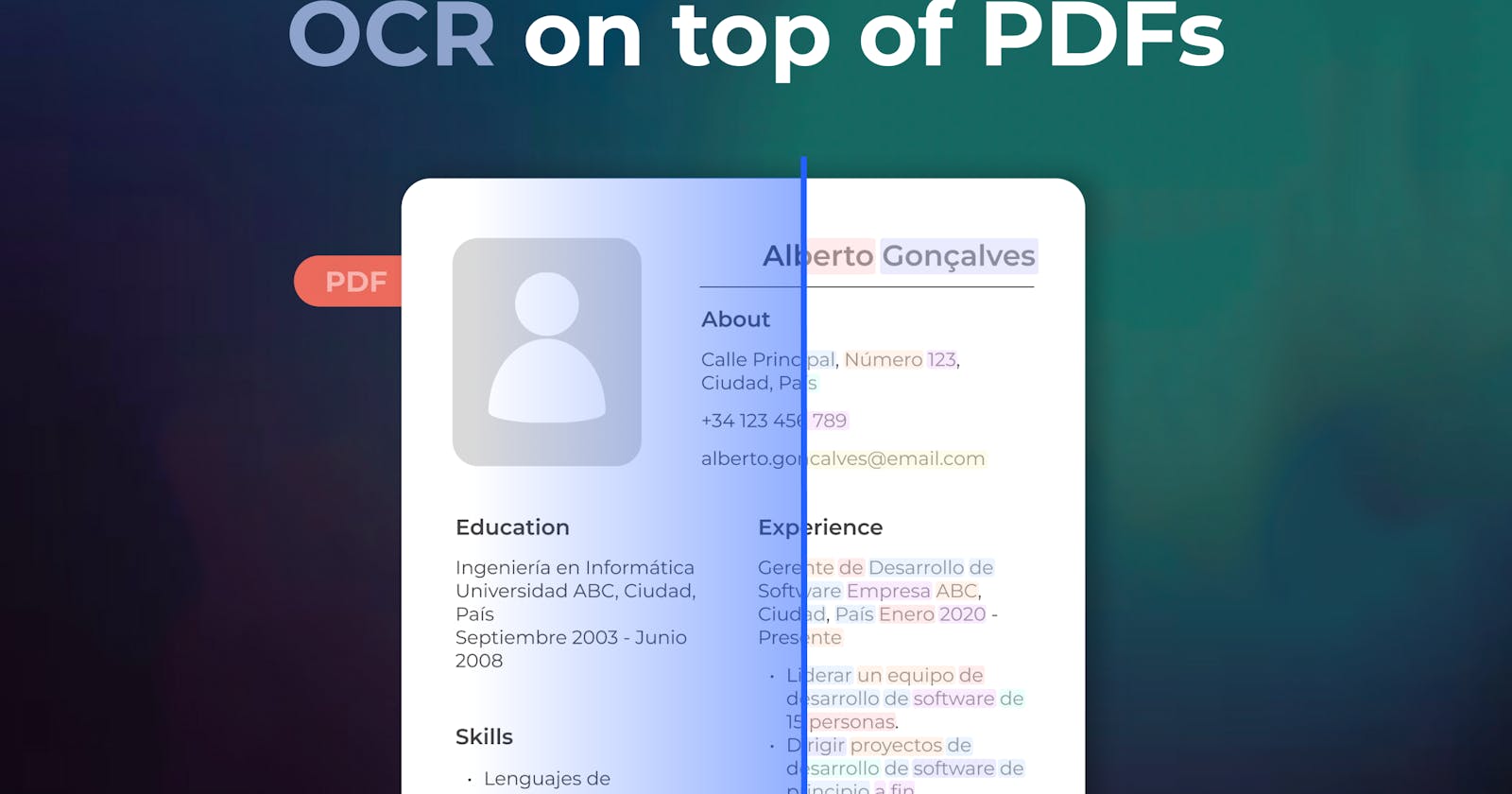
First and foremost, you’ll need to call the Eden AI OCR API in order to extract the pieces of text from your .pdf file. In our case, the .pdf file is just one-page PDF containing strings of text, as shown below in the picture:

Here-after an example of code to use Eden AI to extract bounding boxes of texts from a PDF:
import fitz
import requests
import json
import os
from settings import API_KEY, COLORS
file_path="test_ocr.pdf"
#Eden ai call
headers = {"Authorization": f"Bearer {API_KEY}"}
url = "https://api.edenai.run/v2/ocr/ocr"
data = {"providers": "amazon", "language": "en"}
files = {"file": open(file_path, "rb")}
response = requests.post(url, data= data, files=files, headers=headers)
if response.status_code >= 400:
print("Oupps! something went wrong")
result = response.json()
bboxs = result["amazon"]["bounding_boxes"]
Step 2. Draw the bounding boxes
Having extracted the bounding boxes, you will now need to draw them in the .pdf file. To do so, you will use the PyMuPDF python librarys a high-performance Python library for data extraction, analysis, conversion & manipulation of PDF (and other) documents.
doc = fitz.open(file_path) # open the doc
COLORS_ = [tuple(color_i/255 for color_i in color) for color in COLORS] # change rage from (0-255) to (0-1)
nb_colors = len(COLORS_)
for page in doc:
box = page.mediabox
page_width = box.width
page_height = box.height
for i, bbox in enumerate(bboxs):
left = bbox["left"] * page_width
top = bbox["top"] * page_height
width = bbox["width"] * page_width
height = bbox["height"] * page_height
color = COLORS_[i % nb_colors]
page.draw_rect([left, top, left + width, top + height], color=color, width=1)
file_name, ext = os.path.splitext(file_path)
doc.save(f"{file_name}_bbox{ext}") # save changes
Then, you’ll need to save a new file containing the extracted bounding boxes drawn on the input PDF. In our example, we used a set of multiple colors to draw each bounding box with a color different from its horizontal neighbors.

Use cases for using bounding boxes on PDFs
Bounding boxes are often used in PDFs with OCR (Optical Character Recognition) for various purposes. These bounding boxes are rectangles drawn around specific regions of text or objects within a PDF document. Here are some common use cases for using bounding boxes in PDF OCR:
1. Text Extraction and Recognition
Bounding boxes can be used to isolate and identify individual words, phrases, or paragraphs within a scanned document. This is particularly useful for converting printed or handwritten text into editable digital text.
2. Document Layout Analysis
OCR software can use bounding boxes to analyze the layout and structure of a document. This helps in distinguishing between headers, footers, captions, body text, and other elements, making it easier to maintain the original formatting.
3. Data Extraction
Bounding boxes can be applied to tables, forms, or other structured data within a PDF. OCR software can use these boxes to identify and extract data fields, such as names, dates, addresses, and numbers, for further processing.
4. Redaction and Anonymization
When dealing with sensitive information in PDFs, bounding boxes can be used to highlight or mask specific areas for redaction or anonymization. This ensures that confidential data is protected when sharing or archiving documents.
5. Image Object Recognition
Bounding boxes can be applied to images and graphics within a PDF. OCR tools can recognize and extract text or metadata associated with these images, improving the searchability and accessibility of image-rich documents.
6. Form Field Identification
In interactive PDF forms, bounding boxes can be used to identify and map form fields, such as text fields, checkboxes, and radio buttons. OCR can assist in extracting and processing user input from these forms.
7. Text Translation
Bounding boxes can be used to select specific text segments for translation. OCR can recognize the text within the boxes and then translate it into another language, allowing users to understand content in their preferred language.
8. Content Summarization
Bounding boxes can help identify key sections or paragraphs within a document. OCR can then be used to extract and summarize the content within these boxes, making it easier for users to quickly grasp the document’s main points.
9. Automated Document Classification
Bounding boxes can aid in the automatic classification of documents based on their content. OCR can be used to analyze text within specified regions and categorize documents into predefined groups.
10. Accessibility and Screen Readers
For visually impaired individuals, OCR with bounding boxes is crucial for screen reader applications. Bounding boxes help screen readers navigate and read aloud specific sections of text, images, or other content in PDFs.
These use cases demonstrate the versatility of bounding boxes in PDF OCR applications, helping improve document processing, data extraction, information retrieval, and overall document accessibility.
Conclusion
You’re all set!
Eden AI’s platform offers a seamless pathway to incorporate OCR capabilities into your projects, delivering standardized responses that encompass extracted text and bounding boxes, greatly simplifying the process of information management and analysis!